
최근에 개인 프로젝트를 하나 진행하면서 Open AI API를 연결했는데 그 과정을 글로 남겨볼까 합니다.
gpt-3.5-turbo 모델을 사용했습니다.
프레임워크는 Next.js를 사용했고 버전은 13.4.10, page router를 사용했습니다.
전체 코드는 [Fixpace Repository]에서 확인할 수 있습니다.
서비스가 궁금하신 분들은 여기로 → fixpace.site
Open AI API 키 발급
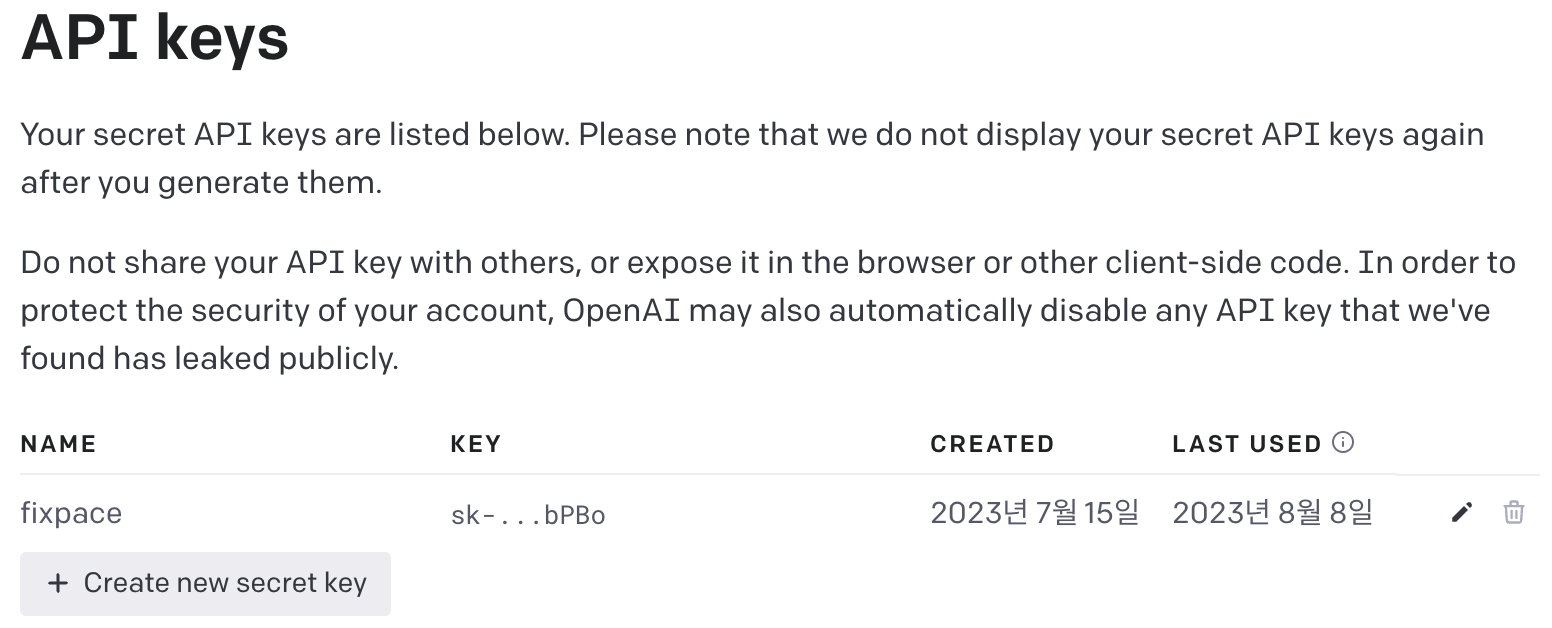
Create new secret key를 이용하여 Open AI API 키를 발급받을 수 있습니다.
저는 키를 받기 위해서 새로운 구글 계정을 하나 만들고 무료 크레딧 $5를 받았습니다. 무료 크레딧은 API 키 최초 발급일로부터 3개월이고, 그 이후에는 만료된다는 것에 유의하세요.
API Route
API 레퍼런스랑 openai-quickstart-node 레포를 많이 참고했습니다.

openai-quickstart-node의 폴더 구조를 보면 다음과 같이 api 폴더 아래에 generate.js가 있는 것을 볼 수 있습니다.
이를 Next.js API Route라고 하는데, pages/api 폴더 내의 모든 파일은 /api/*에 매핑되며 페이지 대신 API 엔드포인트로 처리됩니다.
OpenAI API 키를 노출하지 않기 위해 브라우저에서 직접 API를 요청하는 대신 위와 같이 API 엔드포인트를 생성해야 합니다.
openai-quickstart-node의 api/generate.js를 살펴봅시다. 다만, 레거시 코드를 사용하고 있기에 조금 수정했습니다.
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY, // 서버에서만 사용되므로 NEXT_PUBLIC_ 붙일 필요 x
});
const openai = new OpenAIApi(configuration);
...
try {
const { data } = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: `Suggest three names for an ${animal}` },
],
});
res.status(200).json({ result: data.choices[0].content });
} catch (error) { ... }간단하게 설명하자면,
model: Open AI API는 기능과 가격대가 다른 다양한 모델 세트로 구동됩니다. 여기서의model은 Chat API와 작동하는 모델을 의미하며, 대표적으로 gpt-4, gpt-3.5-turbo, text-davinci-003 등이 있습니다. 더 많은 모델의 종류는 여기를 참고하세요.messages: 대화를 구성하는 메시지 목록입니다.role과content등의 프로퍼티를 가지는 객체 리스트입니다.
예제 코드를 실행하면 다음과 같이 입력한 동물에게 어울리는 3개의 이름을 지어주는 것을 볼 수 있습니다.
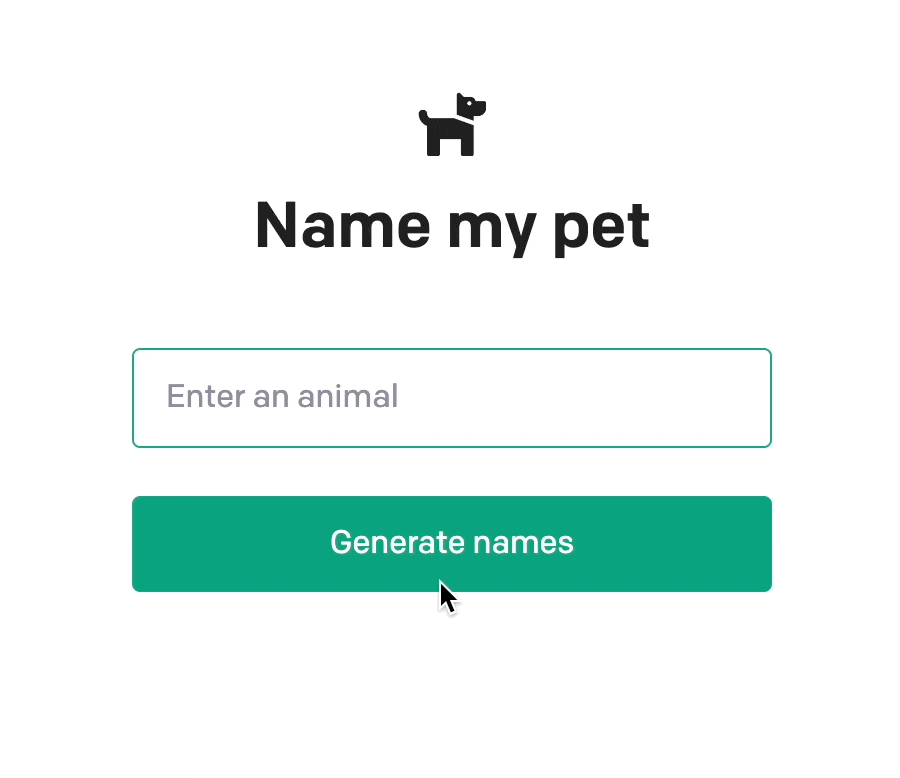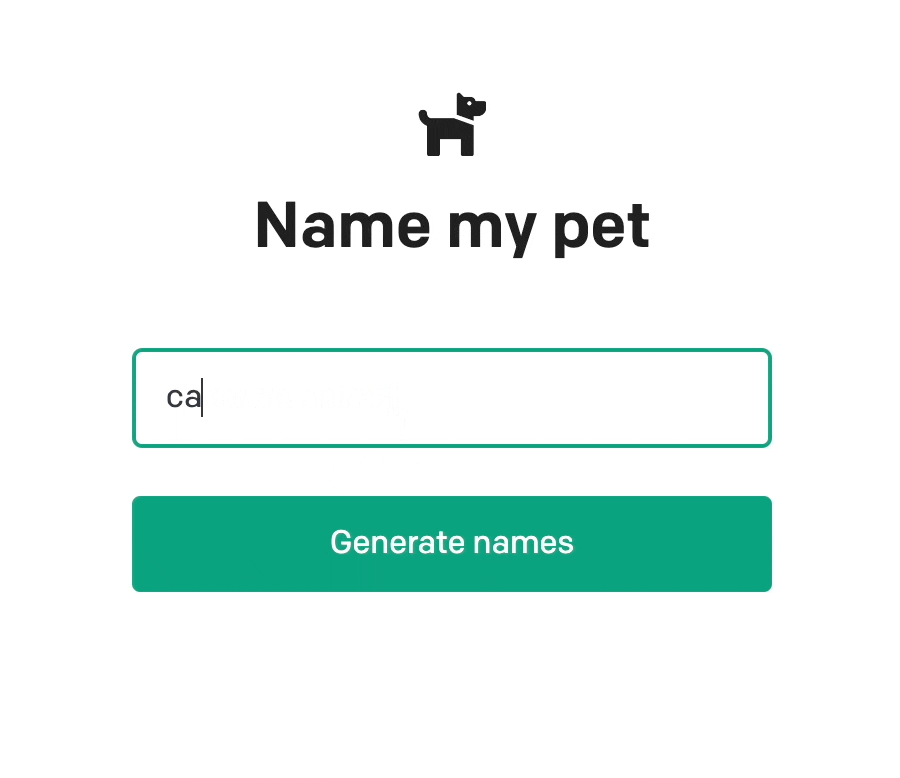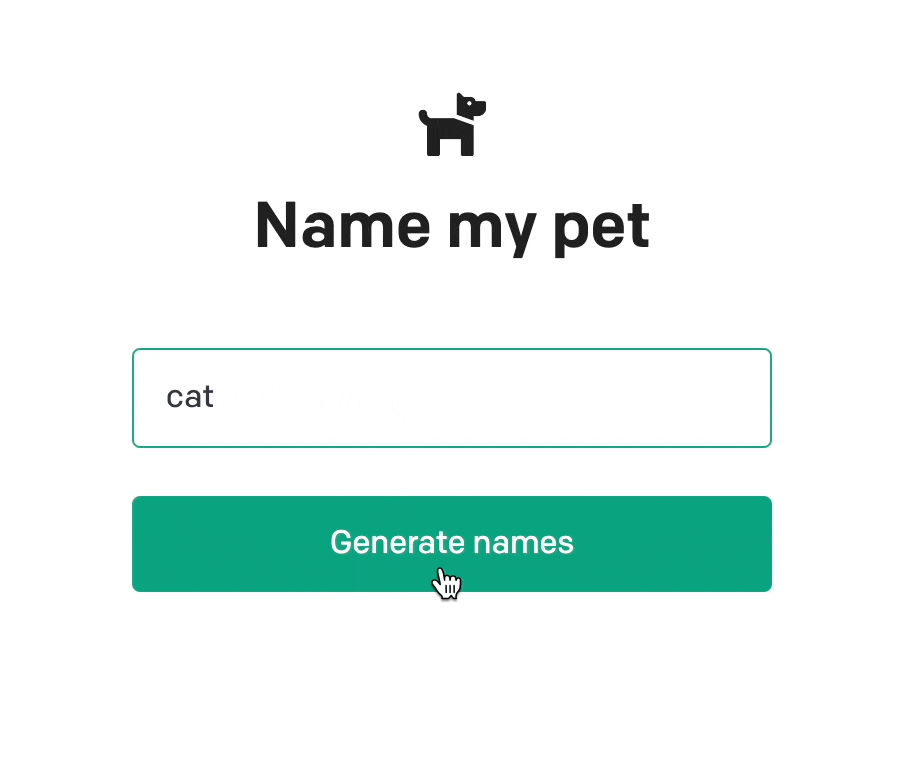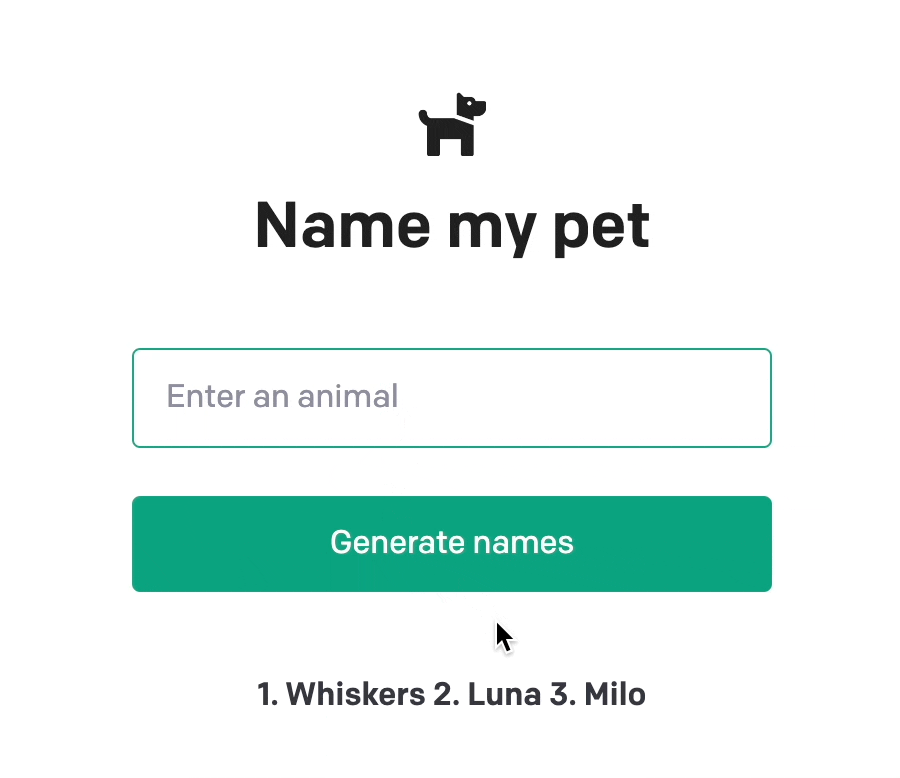
응답은 다음과 같은 구조로 내려옵니다.
{
id: 'chatcmpl-7lfK4I6kctFLOBKImlf0gcyED1FYR',
object: 'chat.completion',
created: 1691594616,
model: 'gpt-3.5-turbo-0613',
choices: [{
index: 0,
message: { role: 'assistant', content: '1. Whiskers\n2. Luna\n3. Simba' },
finish_reason: 'stop'
}],
usage: { prompt_tokens: 24, completion_tokens: 14, total_tokens: 38 }
}원하는 정보가 choices[0]의 message의 content에 담겨져 있는 것을 볼 수 있습니다.
res.status(200).json({ result: data.choices[0].content });
이제 이 정보를 서버 응답 객체에 담아서 보내면 됩니다.
상태 코드를 200으로 설정하고, 비동기 작업의 결과가 포함된 JSON 응답을 전송합니다.
res에 대해 더 자세히 알고 싶으면 여기를 참고하세요.
API 호출
/api/*로 다음과 같이 호출하면 된다.
const response = await fetch("/api/generate", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ animal: animalInput }),
});
const data = await response.json();자 Open AI API 연결이 완료되었습니다.

쉽다고? 아닐텐데..
Vercel 배포 후 에러 (504)
배포는 Vercel로 했습니다.
가비아에서 도메인도 구매해서 두근거리는 마음으로 배포 사이트에서 기능을 테스트 해보는데.. 개발 중에는 본 적이 없던 오류가 랜덤으로 발생하기 시작했습니다.


에러의 원인은 Vercel에 있었습니다.

저는 Vercel의 hobby plan을 사용하고 있는데 해당 플랜은 Serverless Function의 execution timeout이 10s입니다.
간혹 응답이 늦어져 10초가 넘어가는 경우 에러가 발생했던 것입니다.
위 사진도 보면 8.26s일 때는 에러가 발생하지 않았지만, 10.89s일 때 에러가 발생한 것을 볼 수 있습니다.
그러면 이 에러를 어떻게 해결할 수 있을까요?
Edge Function을 사용합시다!
Edge Function, Edge API Route
Vercel에서도 타임아웃의 대안으로 Edge Function을 제안하고 있습니다. (Edge Function limit은 30s)
잠시 Edge Computing에 대해 짚고 넘어가자면, Edge Computing은 사용자 또는 데이터 소스의 물리적인 위치(DB)나 그 근처에서 컴퓨팅을 수행하는 것을 말합니다. 따라서 사용자의 단말 장치와 가까운 위치에서 컴퓨팅 서비스를 처리하면 사용자는 더 빠르고 안정적인 서비스를 제공받을 수 있습니다. - Edge Computing이란?
Vercel의 Edge Function은 평균적으로 서버리스 함수보다 비용과 성능 면에서 더 효율적인 Edge Runtime을 사용합니다.
Edge Function은 사용자 근처에서 실행될 수 있으므로 네트워크 요청이 Serverless Function보다 더 짧은 거리를 이동하고 더 적은 비용이 발생합니다. 또한, 훨씬 짧은 지연 시간으로 사용자에게 응답을 전달할 수 있습니다.
따라서 짧은 시간 내에 요청이 완료되지 않으면 실패하는 API와 상호 작용하는 등 네트워크를 통해 최대한 빠르게 데이터와 상호 작용해야 할 때 유용합니다.
기존의 API Route에서 Edge Runtime을 사용하기 위해서는 다음 코드만 추가하면 됩니다.
export const config = {
runtime: "edge",
regions: "icn1"
};추가로, Edge Function의 효율적인 라우팅을 위해 함수를 실행할 지역을 Vercel Edge Network에 구성할 수 있습니다.
저는 서울 지역의 ID를 Edge Function의 config 객체에 추가하였습니다.
Edge API Route를 사용하는 예제 코드는 다음과 같습니다.
import type { NextRequest } from 'next/server'
export const config = {
runtime: 'edge',
}
export default async function handler(req: NextRequest) {
return new Response(
JSON.stringify({
name: 'Jim Halpert',
}),
{
status: 200,
headers: {
'content-type': 'application/json',
},
}
)
}참고로 해당 예제에서는 사용하지 않았지만 next/server에서 헬퍼 함수인 NextRequest, NextResponse를 가져와서 사용할 수 있습니다. 이는 미들웨어와 Edge API Route에서 사용할 수 있는 server-only 헬퍼입니다. 요청을 더 잘 제어하기 위해서 native Request interface를 직접 대체하는 NextRequest를 사용할 수 있습니다.
📍 Request / NextRequest / NextAPIRequest 차이 [출처]
- Request is the standard Web API that you use in the browser and in recent versions of Node.js
- NextRequest is a subclass of Request that adds several properties and methods. It's used in middleware.
- NextApiRequest extends Node.js' IncomingMessage (from node:http) and also adds several helpers to it. It's used in API routes
저는 NextResponse를 사용하여 다음과 같이 JSON을 반환해주었습니다.
const text = data.choices[0].message?.content;
return NextResponse.json({ text });
Edge Function은 axios와 호환되지 않는다.
자 이제 Edge API Route로 바꿨으니, 잘 동작할까요?

Edge Function은 fetch Web API를 지원하고 axios와 같은 라이브러리와는 호환되지 않습니다.
하지만 OpenAI 라이브러리가 내부적으로 axios를 사용하면서 위와 같이 adapter is not a function 오류가 발생한 것 같네요.
그래서 그냥 Edge Function이 권장하는 fetch를 다음과 같이 사용했고 더이상 에러가 발생하지 않았습니다.
const response = await fetch("https://api.openai.com/v1/chat/completions", {
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${process.env.OPENAI_API_KEY}`,
},
method: "POST",
body: JSON.stringify(payload),
});
const data = await response.json();
Edge Function 적용 결과

응답을 받을 때까지 보통 6s~9s 정도 걸리는 것 같습니다.
서버리스 함수가 자주 10s를 넘기던 것을 생각하면 지연 시간이 꽤 줄은 것으로 보입니다.


Vercel Log를 확인했을 때 타입이 Serverless Function에서 Edge Function으로 바뀐 것을 볼 수 있습니다.
응답 지연시간이 감소했고, Vercel hobby plan에서 Edge Function의 limit이 30s이기 때문에 더이상 504에러로 인해 고통받을 일은 없을 것 같네요. 그래도 에러 핸들링 코드는 작성했습니다.
여기까지 Open AI API를 연결하는 방법과 연결 도중 발생한 에러를 해결하는 방법에 대해 알아보았습니다.
'프로그래밍 > Next' 카테고리의 다른 글
| [성능 개선] 리액트 렌더링 최적화하기 (1) | 2023.05.19 |
|---|---|
| [성능 개선] Next.js 프로젝트 LCP 최적화하기 (0) | 2023.05.11 |
| 캐싱, Cache-Control 알아보기 🥹 (0) | 2023.02.01 |
| [Next] Dynamic Routes / Router Hook / Catch All (0) | 2022.07.08 |
| [Next] Patterns / Fetching Data / Redirect & Rewrite / SSR (0) | 2022.07.08 |